


Update (Sept. 28, 2012): the method for archiving tweets using IFTTT and Dropbox describe here no longer works thanks to Twitter cutting off IFTTT’s access for anything except posting tweets to Twitter. I am looking into alternatives, but don’t know of any drop-in replacements currently.
Justin Blanton recently posted an approach to archiving tweets using plain text and Dropbox. In short, he’s using IFTTT.com (also known as If This Then That, a service that allows you to setup triggers and actions for events in common web services) to append every tweet to a plain text file in his Dropbox account.
In turn, Brett Terpstra took Justin’s IFTTT recipe and modified it to use Markdown formatting.
Now I have added my own spin to the idea by creating a script that I run via Hazel to automatically break the tweets into files by month. You could, of course, run the script using some other method; I just prefer the ease-of-use of Hazel.
Setting up
For this to work, you need three things:
- The IFTTT recipe
- The archiving script (also available inline below)
- A Hazel rule to pull everything together (or some other way to automatically invoke the script and pass it the filename for your initial archive file)
When you have those three things in place, shortly after you publish a tweet it will be appended to a plain text in Dropbox by IFTTT, then subsequently sorted into archival files by month by the archival script. The script also (optionally) expands Twitter’s shortened t.co links into the actual URL you posted.
For those who want a little more hand-holding, here’s specifically how to get all the various pieces lined up.
IFTTT configuration
You need to change a couple things in the IFTTT recipe to make it work for you. In particular, the default folder path (ifttt/twitter) is very uninspired. You also need to change the name of the file to your Twitter username. If you want, you can use a different file extension (like .md).
(Note that it’s entirely possible to archive multiple Twitter accounts using this method, but you will likely need multiple IFTTT accounts; so far as I know it is not possible to link multiple Twitter accounts to a single IFTTT account.)
Once you’ve got the recipe activated in your IFTTT account, post a tweet and make sure that it is showing up in your Dropbox (should happen within 15 minutes, or you can run the IFTTT recipe explicitly).
Archival script
Setting up the archival script will require a little bit of command-line work, but nothing too scary. To get started, you can download the script from GitHub, or create a file called archive-tweets.py in your favorite text editor and copy and paste:
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
This script parses a text file of tweets (generated by [IFTTT][1],
for instance) and sorts them into files by month. You can run it
manually from the command line:
cd /path/to/containing/folder
./archive-tweets.py /path/to/@username.txt
Or run it automatically using [Hazel][2] or similar. The script
expects that you have a file named like your Twitter username with
tweets formatted and delimited like so:
My tweet text
[July 04, 2012 at 06:48AM](http://twitter.com/link/to/status)
- - -
And that you want your tweets broken up by month in a subfolder next
to the original file. You can change the delimiting characters between
tweets and the name of the final archive file using the config variables
below.
By default, this script will also try to resolve t.co shortened links
into their original URLs. You can disable this by setting the
`expand_tco_links` config variable below to `False`.
[1]: http://ifttt.com/
[2]: http://www.noodlesoft.com/hazel.php
'''
# CONFIG: adjust to your liking
separator_re = r'\s+- - -\s+' # IFTTT adds extra spaces, so have to use a regex
final_separator = '\n\n- - -\n\n' # What you want in your final montly archives
archive_directory = 'archive' # The sub-directory you want your monthly archives in
expand_tco_links = True # Whether you want t.co links expanded or not (slower!)
sanitize_usernames = False # Whether you want username underscores backslash escaped
# Don't edit below here unless you know what you're doing!
import sys
import os.path
import re
import dateutil.parser
import urllib2
# Utility function for expanding t.co links
def expand_tco(match):
url = match.group(0)
# Only expand if we have a t.co link
if expand_tco_links and (url.startswith('http://t.co/') or url.startswith('https://t.co/')):
final_url = urllib2.urlopen(url, None, 15).geturl()
else:
final_url = url
# Make link self-linking for Markdown
return '<' + final_url.strip() + '>'
# Utility function for sanitizing underscores in usernames
def sanitize_characters(match):
if sanitize_usernames:
return match.group(0).replace('_', r'\_')
else:
return match.group(0)
# Grab our paths
filepath = sys.argv[1]
username, ext = os.path.splitext(os.path.basename(filepath))
root_dir = os.path.dirname(filepath)
archive_dir = os.path.join(root_dir, archive_directory)
# Read our tweets from the file
file = open(filepath, 'r+')
tweets = file.read()
tweets = re.split(separator_re, tweets)
# Clear out the file
file.truncate(0)
file.close()
# Parse through our tweets and find their dates
tweet_re = re.compile(r'^(.*?)(\[([^\]]+)\]\([^(]+\))$', re.S)
# Link regex derivative of John Gruber's: http://daringfireball.net/2010/07/improved_regex_for_matching_urls
link_re = re.compile(r'\b(https?://(?:[^\s()<>]+|\(([^\s()<>]+|(\([^\s()<>]+\)))*\))+(?:\(([^\s()<>]+|(\([^\s()<>]+\)))*\)|[^\s`!()\[\]{};:\'".,<>?«»“”‘’]))', re.I)
dated_tweets = {}
for tweet in tweets:
if len(tweet) > 0:
# Parse our tweet
matched_tweet = tweet_re.match(tweet)
# Replace t.co links with expanded versions
sanitized_body = re.sub(r'@[a-z0-9]*_[a-z0-9_]+', sanitize_characters, matched_tweet.group(1))
formatted_tweet = link_re.sub(expand_tco, sanitized_body) + matched_tweet.group(2)
# Grab our date, and toss the tweet into our dated dictionary
date = dateutil.parser.parse(matched_tweet.group(3)).strftime('%Y-%m')
if date not in dated_tweets:
dated_tweets[date] = []
dated_tweets[date].append(formatted_tweet)
# Now we have our dated tweets; loop through them and write to disk
for date, tweets in dated_tweets.items():
month_path = os.path.join(archive_dir, username + '-' + date + ext)
# Construct our string with a trailing separator, just in case of future tweets
tweet_string = final_separator.join(tweets) + final_separator
# Append our tweets to the archive file
file = open(month_path, 'a')
file.write(tweet_string)
file.close()
# All done!I like to save the archive-tweets.py file in my Dropbox right next to my @ianbeck.txt archival file (makes things easy to keep track of). If you have changed the formatting of the
Next, you need to ensure that the script can be executed. To do so, open /Applications/Utilities/Terminal.app. This example code assumes that you are using the default settings for the IFTTT recipe and have saved the script in the same Dropbox folder, so adjust the path as needed and then run this command in Terminal:
chmod +x ~/Dropbox/ifttt/twitter/archive-tweets.py
You should also create the folder where your monthly archive files will live. By default it should be called archive, but you can use something else if you want.
Lastly, you might want to modify some settings in the script. There are two things you might need to adjust:
- If you have modified the delimiter between tweets in the IFTTT recipe, you need to specify what you are using in the script
- If you do not want t.co links to be expanded, you need to disable that in the script
- If you want your monthly archives in a folder named something other than
archive, you need to specify your preferred folder name
You can find the configuration variables on line 34, or search for “# CONFIG“.
Hazel workflow
Now that the main moving pieces are in place you need to setup your Hazel workflow to automatically run the script every so often. Here’s what mine looks like:
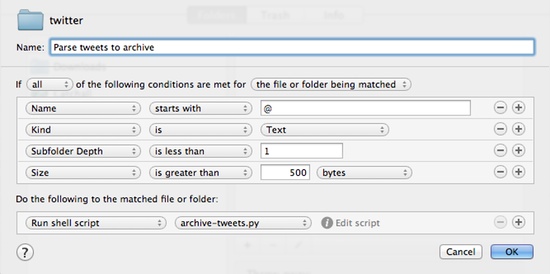
The important bits are having the name start with the “@” symbol, making sure that the subfolder depth is less than 1, and sticking a minimum file size in there (to make sure the script doesn’t get endlessly executed when the file is empty).
Why am I doing this, anyway?
To be honest, most people will probably not care about the fact that Twitter only allows you to access your 3200 most recent tweets. For most of us, tweets are ephemeral; you post it, your friends read it, and that’s that. If you have something you think is particularly clever or worth saving, you can mark it as a favorite and access it whenever you like.
For myself, though, I like having a record of the things that I write, even if it’s something stupid like, “Wow, my balaclava is particularly itchy today.” Why? Because every so often, I remember tweeting something that I need to reference (a link, a prior opinion, etc.), and searching Twitter always fails me. With the above archival setup in place, though, I can easily search for it using the tools built into my computer, and since the archive files are plain text they are as future-proof as I can get, extremely easy to work with, and won’t take up much space in my Dropbox.
Whether having access to your tweets down the road is important to you or not is something you’ll have to decide on your own. If it is, though, this is a pretty easy way to save them despite its geeky underpinnings.
Updates and corrections
July 5, 2012
Dr. Drang points out that @hugovk is the original creator of the IFTTT Twitter-to-Dropbox workflow, not Justin Blanton as I originally thought. Additionally, Dr. Drang offers a script for converting past ThinkUp databases of tweets into plain text format.
Brett Terpstra meanwhile has been hacking away with both my script above and Dr. Drang’s script, and currently has his modifications available on GitHub. I expect he will post his final workflow to his blog once he has them finalized. Good stuff.
July 6, 2012
I have updated the shell script (modified version is on GitHub or inline above) and added the following:
- All URLs are now converted to self-linking URLs for ease of parsing as Markdown:
<http://wherever.com> - Underscores in usernames are optionally escaped with a backslash in order to avoid italicizing:
@some\_name(this is off by default, but you can enable it in the CONFIG section; I just have a friend named @_squark_ and was getting annoyed at his italicized name)
Note that neither of these changes is retroactive, so you will have to modify your existing archive file(s) if you want consistency.
No responses to “Archiving tweets using IFTTT and Dropbox”
Leave a response